Rows: 1,236
Columns: 8
$ case <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 1…
$ bwt <int> 120, 113, 128, 123, 108, 136, 138, 132, 120, 143, 140, 144, …
$ gestation <int> 284, 282, 279, NA, 282, 286, 244, 245, 289, 299, 351, 282, 2…
$ parity <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ age <int> 27, 33, 28, 36, 23, 25, 33, 23, 25, 30, 27, 32, 23, 36, 30, …
$ height <int> 62, 64, 64, 69, 67, 62, 62, 65, 62, 66, 68, 64, 63, 61, 63, …
$ weight <int> 100, 135, 115, 190, 125, 93, 178, 140, 125, 136, 120, 124, 1…
$ smoke <int> 0, 0, 1, 0, 1, 0, 0, 0, 0, 1, 0, 1, 1, 1, 0, 0, 1, 1, 0, 1, …Linear Regression
Baby Weights
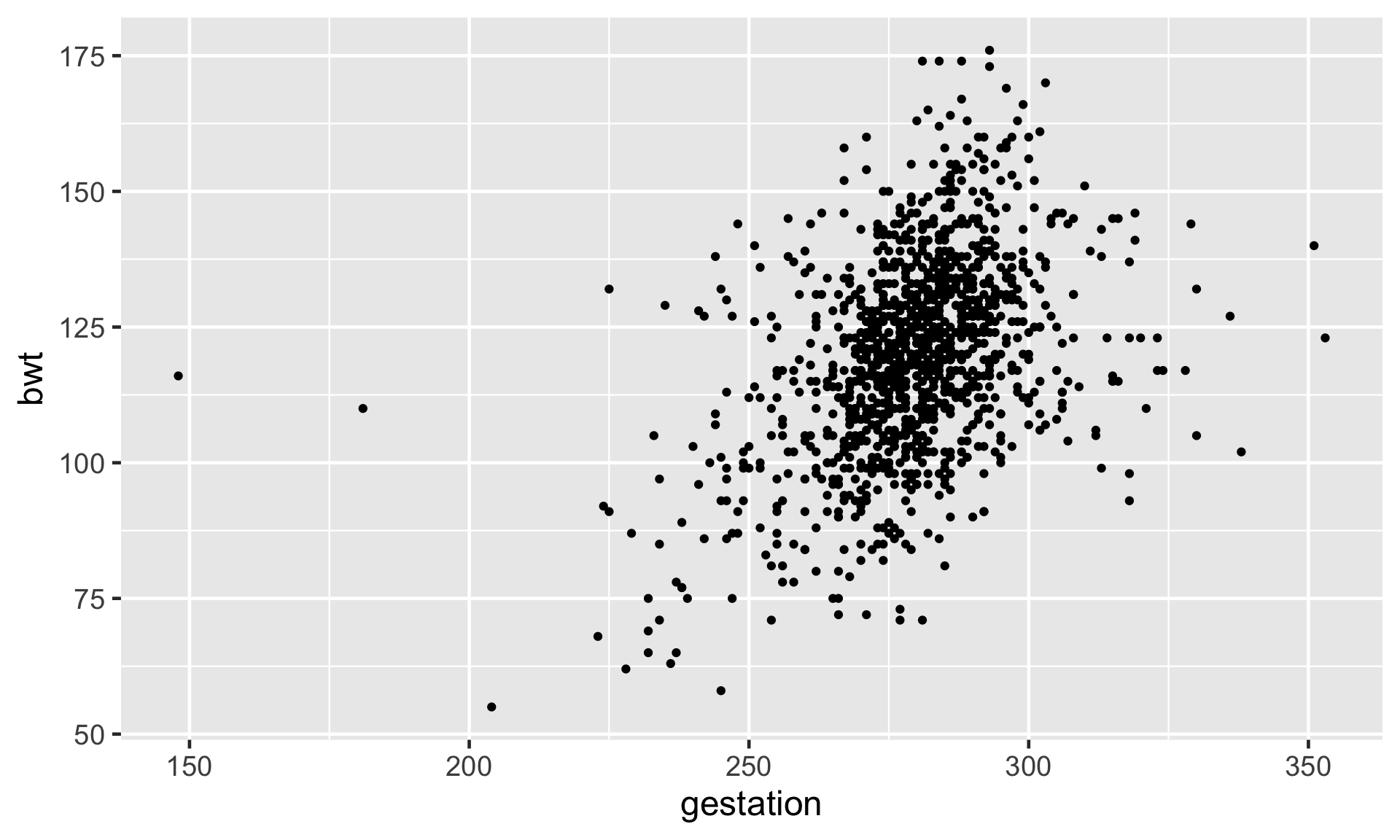
Baby Weights
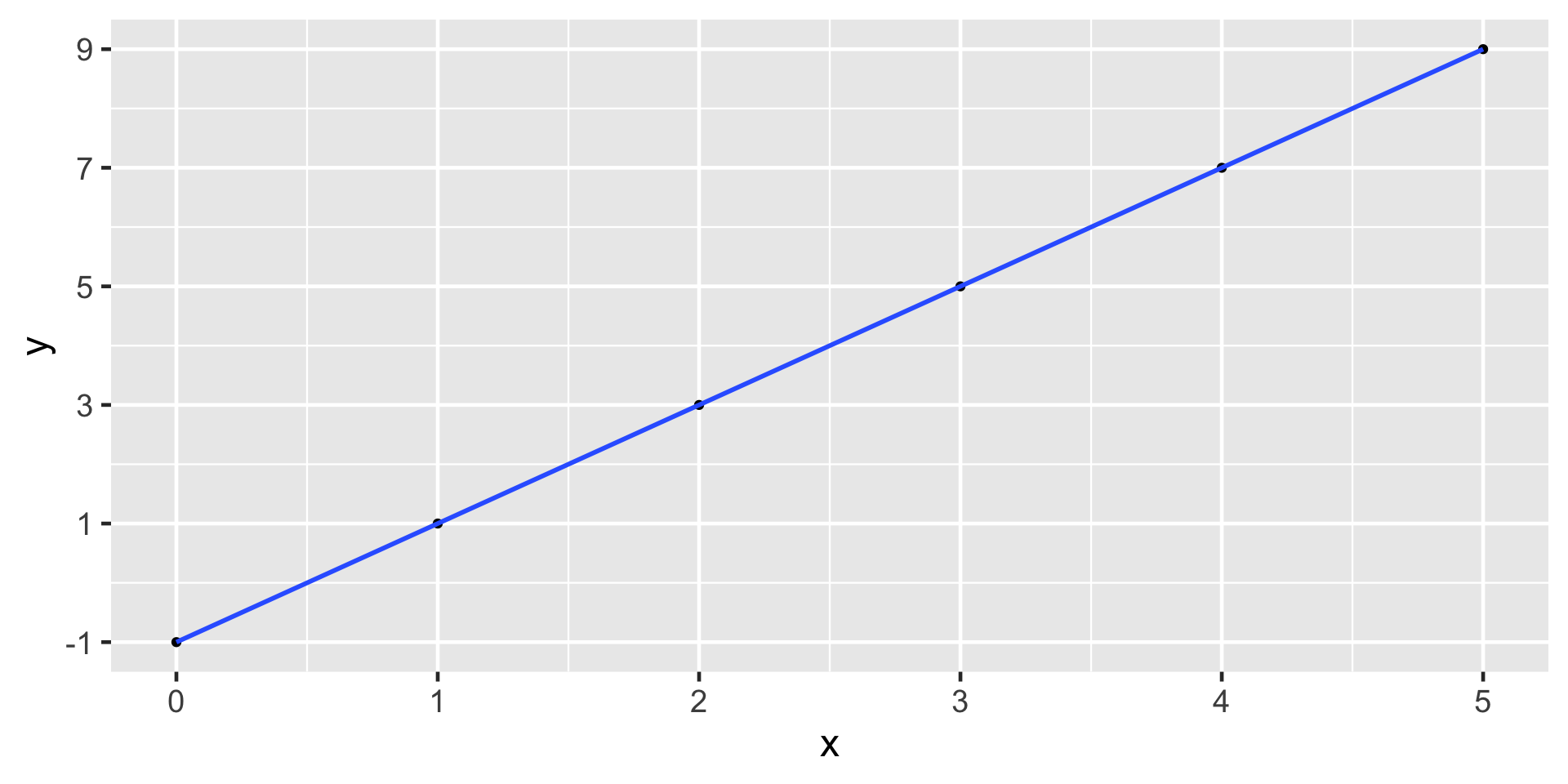
Linear Equations Review
Recall from your previous math classes
\(y = mx + b\)
where \(m\) is the slope and \(b\) is the y-intercept
e.g. \(y = 2x -1\)
Notice anything different between baby weights plot and this one?
Interpretation of estimates
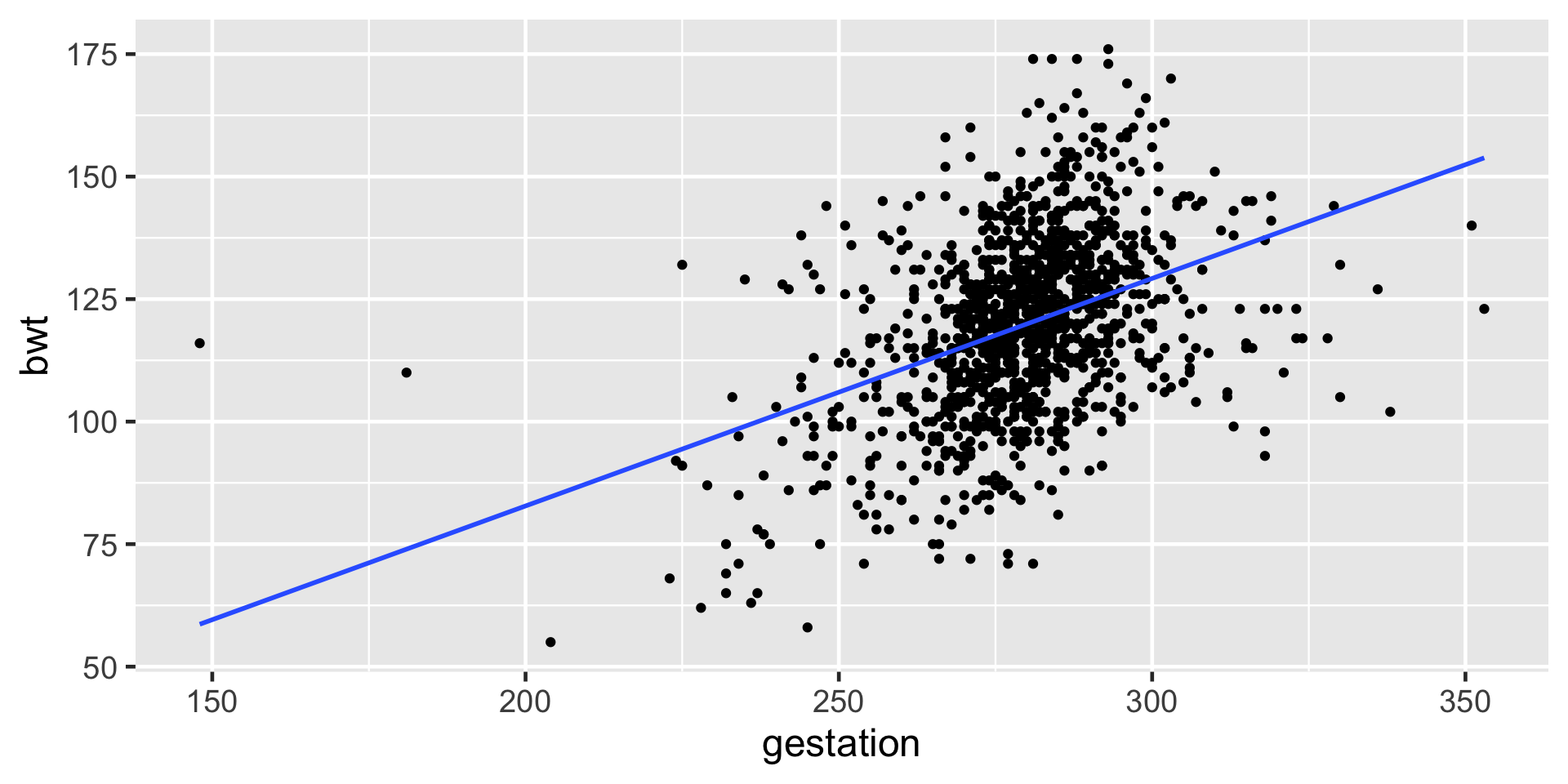
\(\hat{\beta_1} = 0.464\) which means for one unit(day) increase in gestation period the expected increase in birth weight is 0.464 ounces.
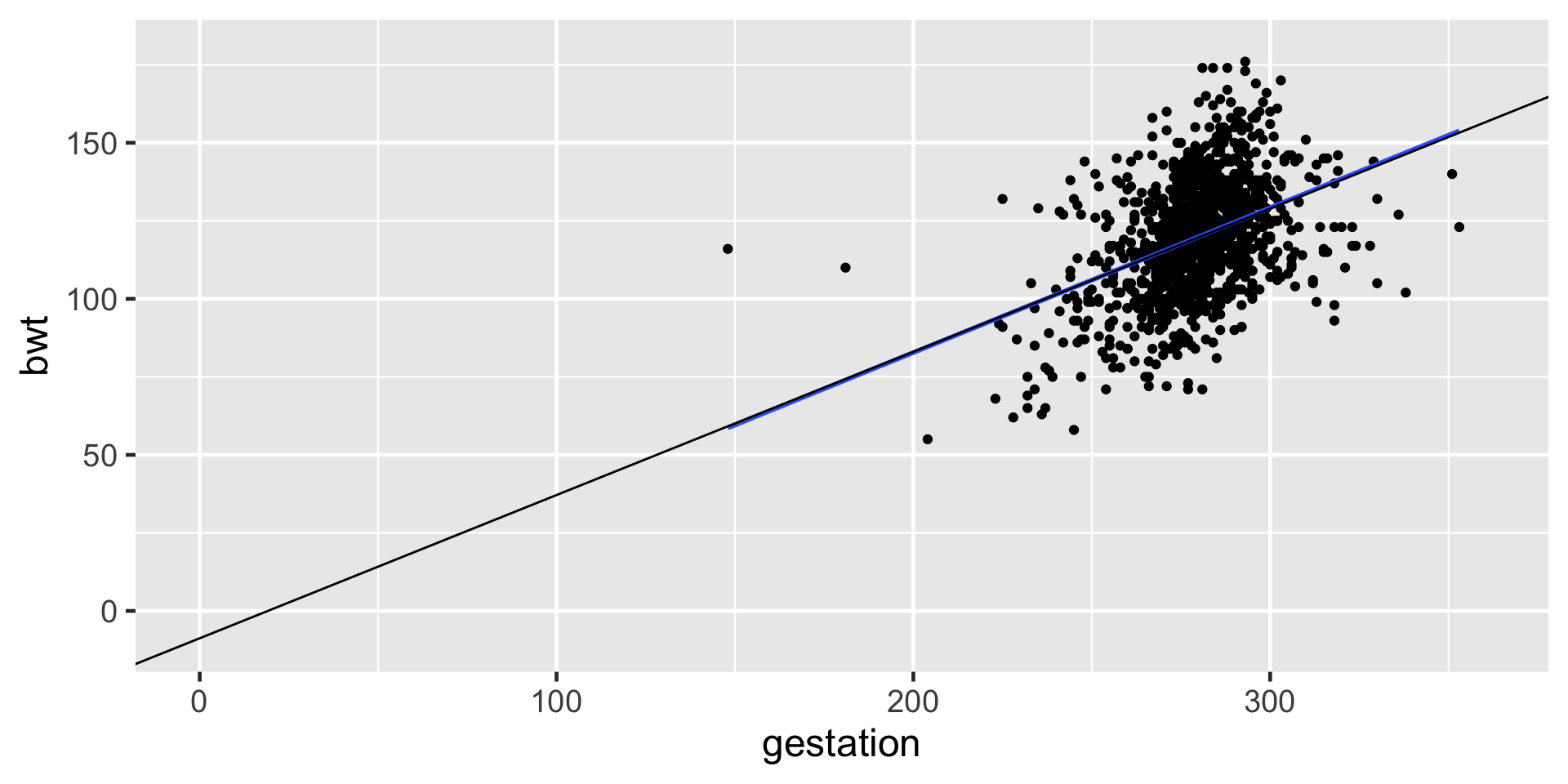
\(\hat{\beta_0} = -10.1\) which means for gestation period of 0 days the expected birth weight is -10.1 ounces!!!!!!!! (does NOT make sense)
Baby number 148
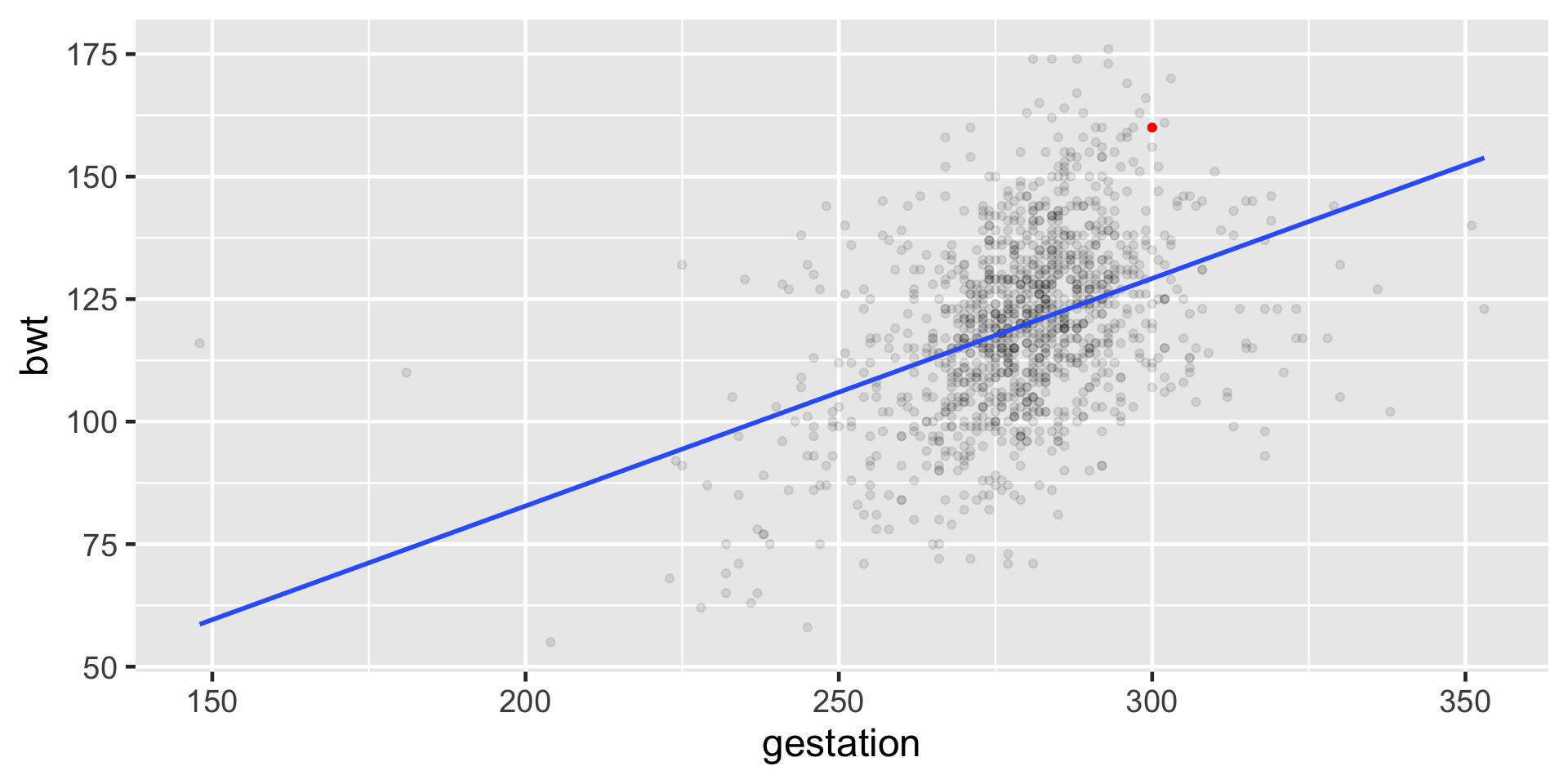
Residual for i = 148
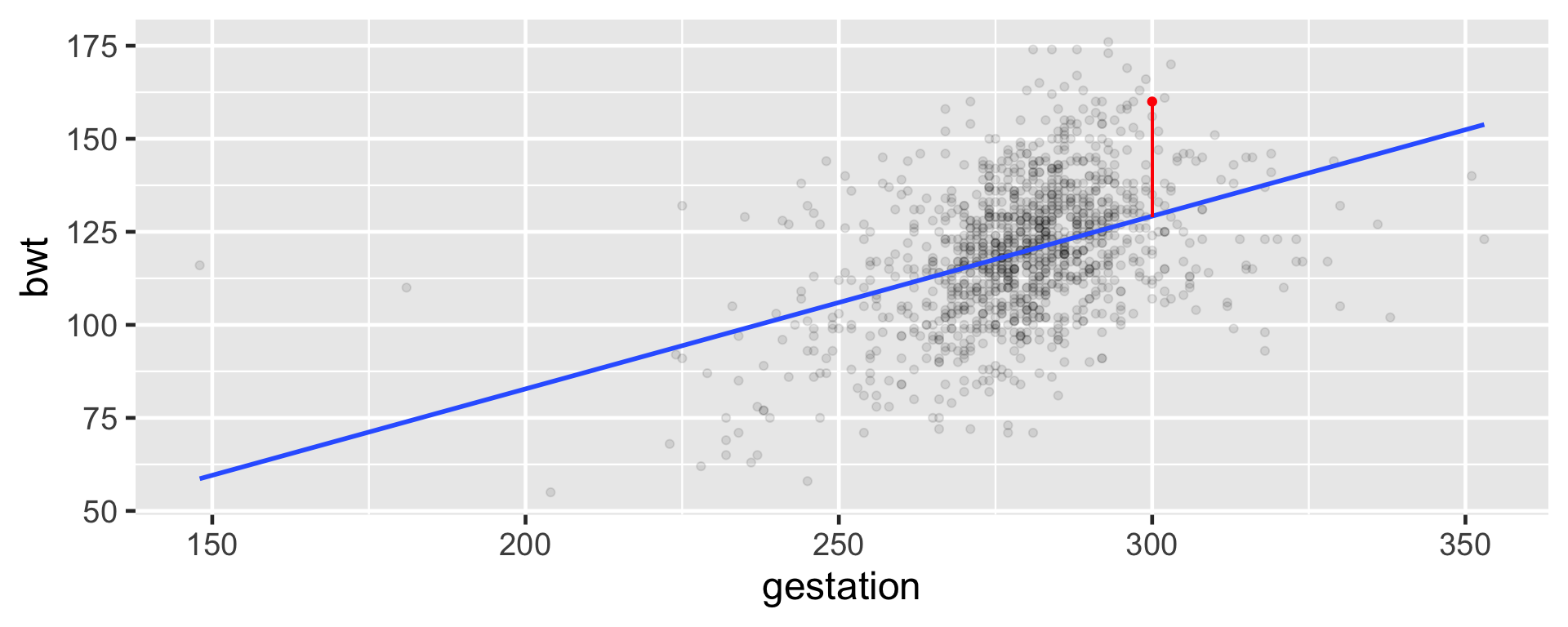
\(\mu_{148} = 160\)
\(\hat \mu_{148}\) = 129.1
\(e_{148} = \mu_{148} - \hat \mu_{148}\)
\(e_{148} =\) 30.9
Linearity
- Probably the most important condition
- The data should have a linear trend
- If the data illustrate a non-linear trend, then more advanced regression methods could be considered
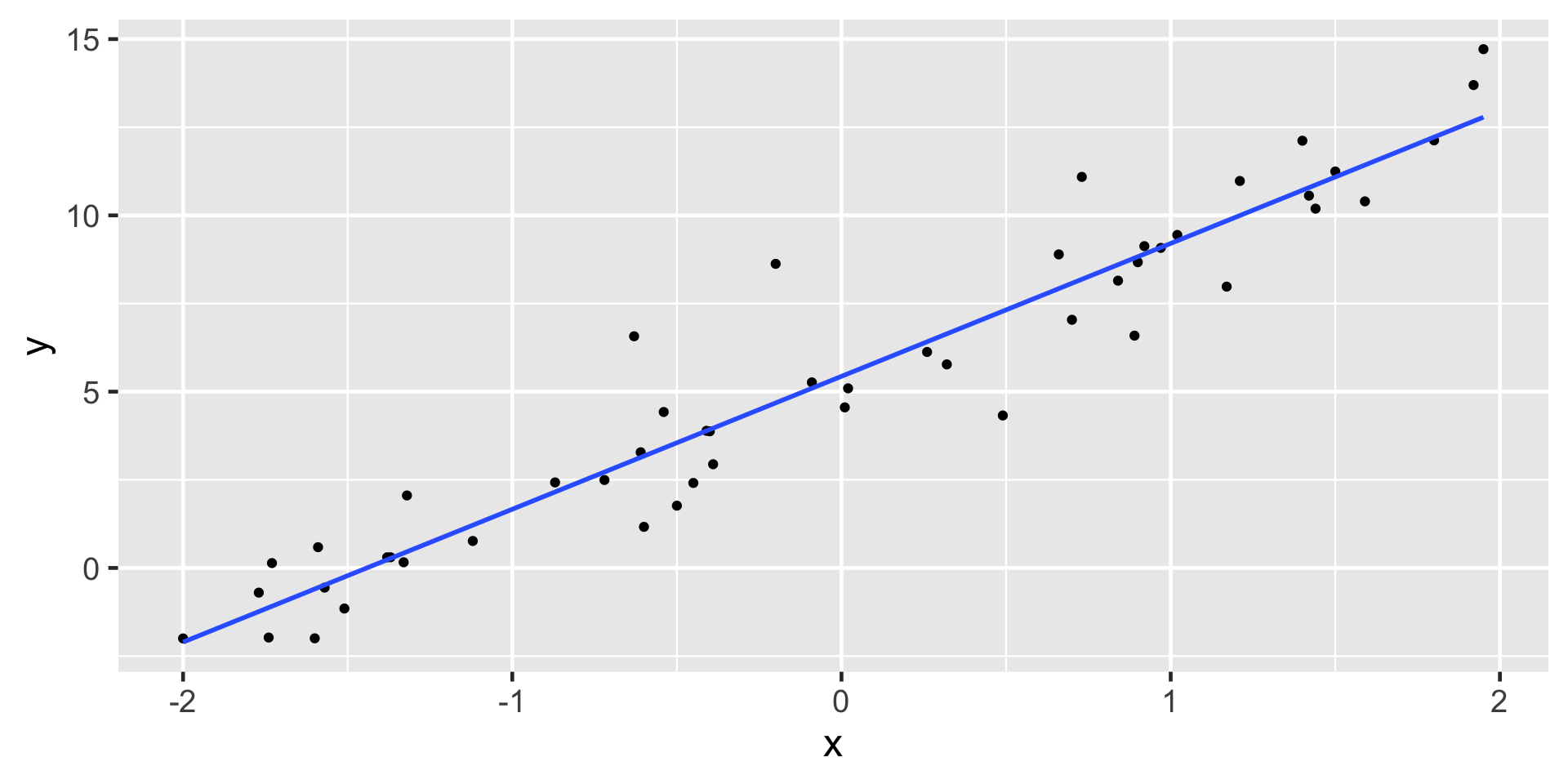
Linearity
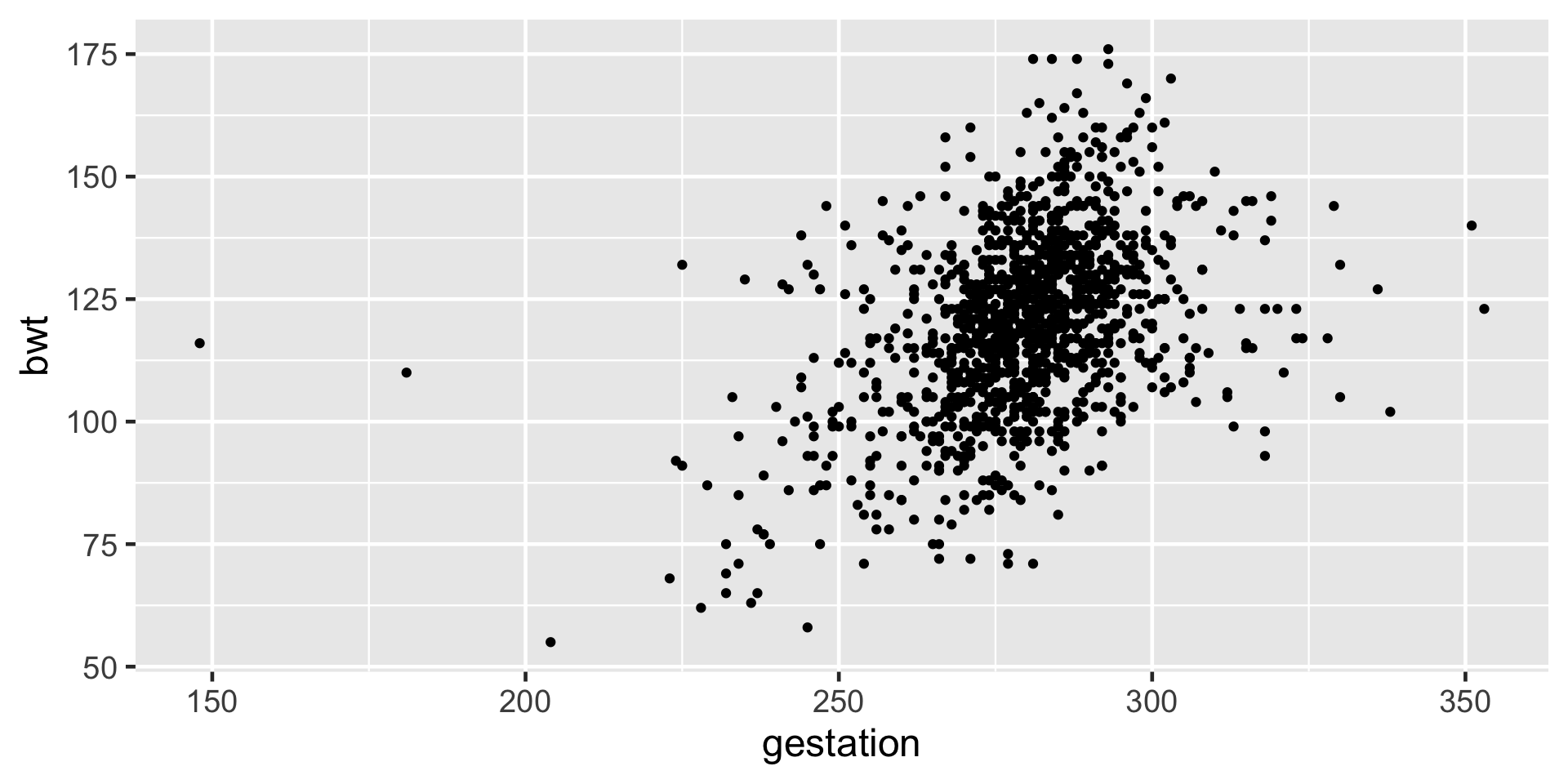
A residual plot is one where the residuals are plotted against the explanatory variable.
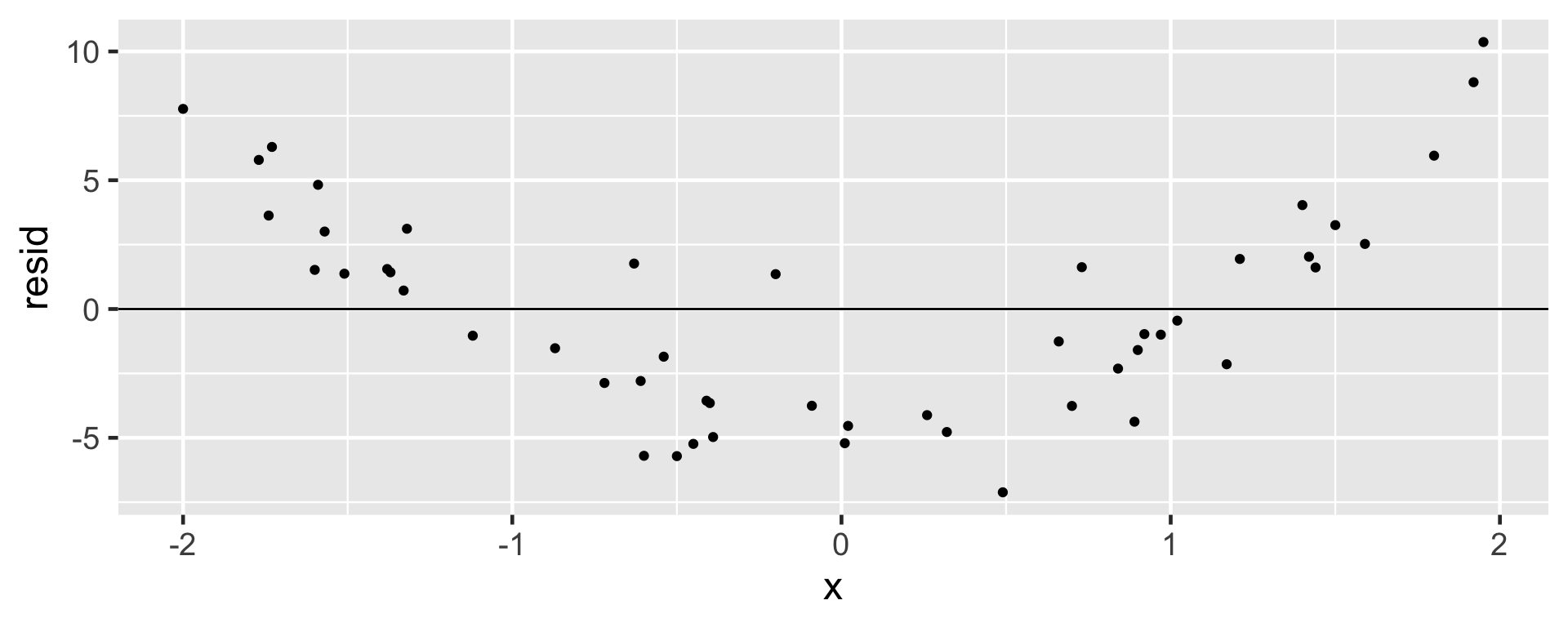
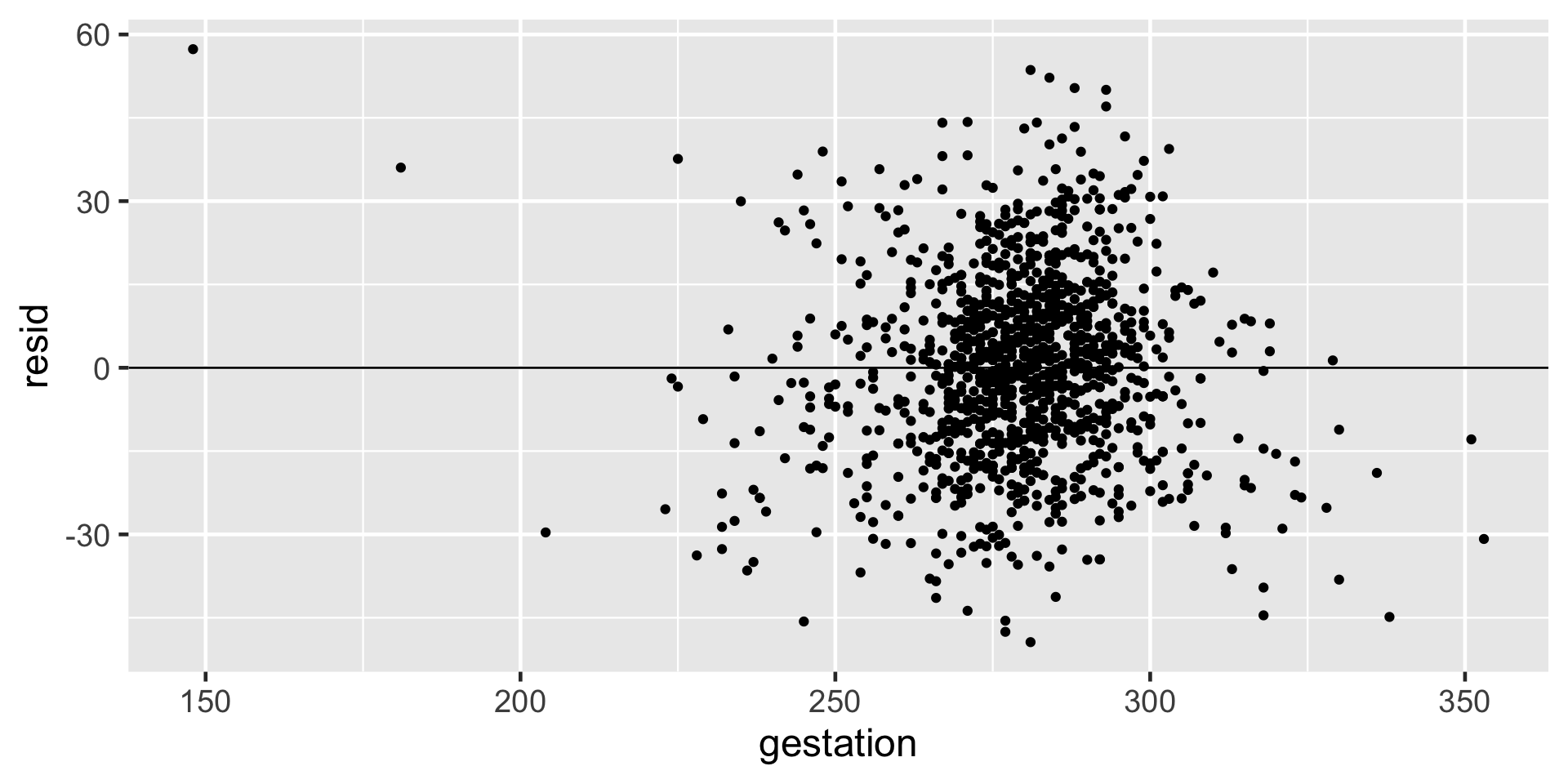
- Points in the residual plot must be randomly scattered, with no pattern, and “close” to 0.
Non-linear Trend
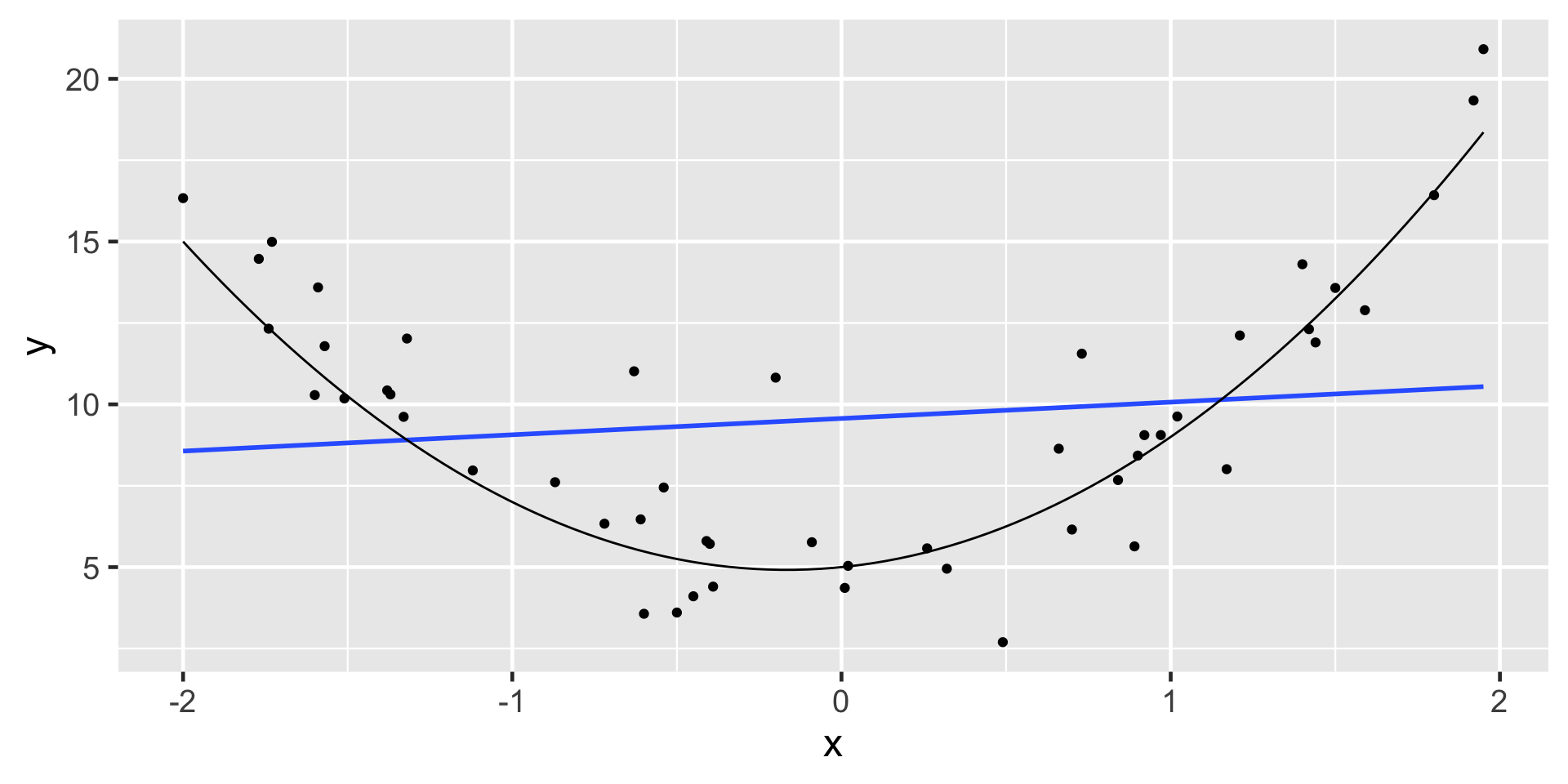
Linear model not appropriate
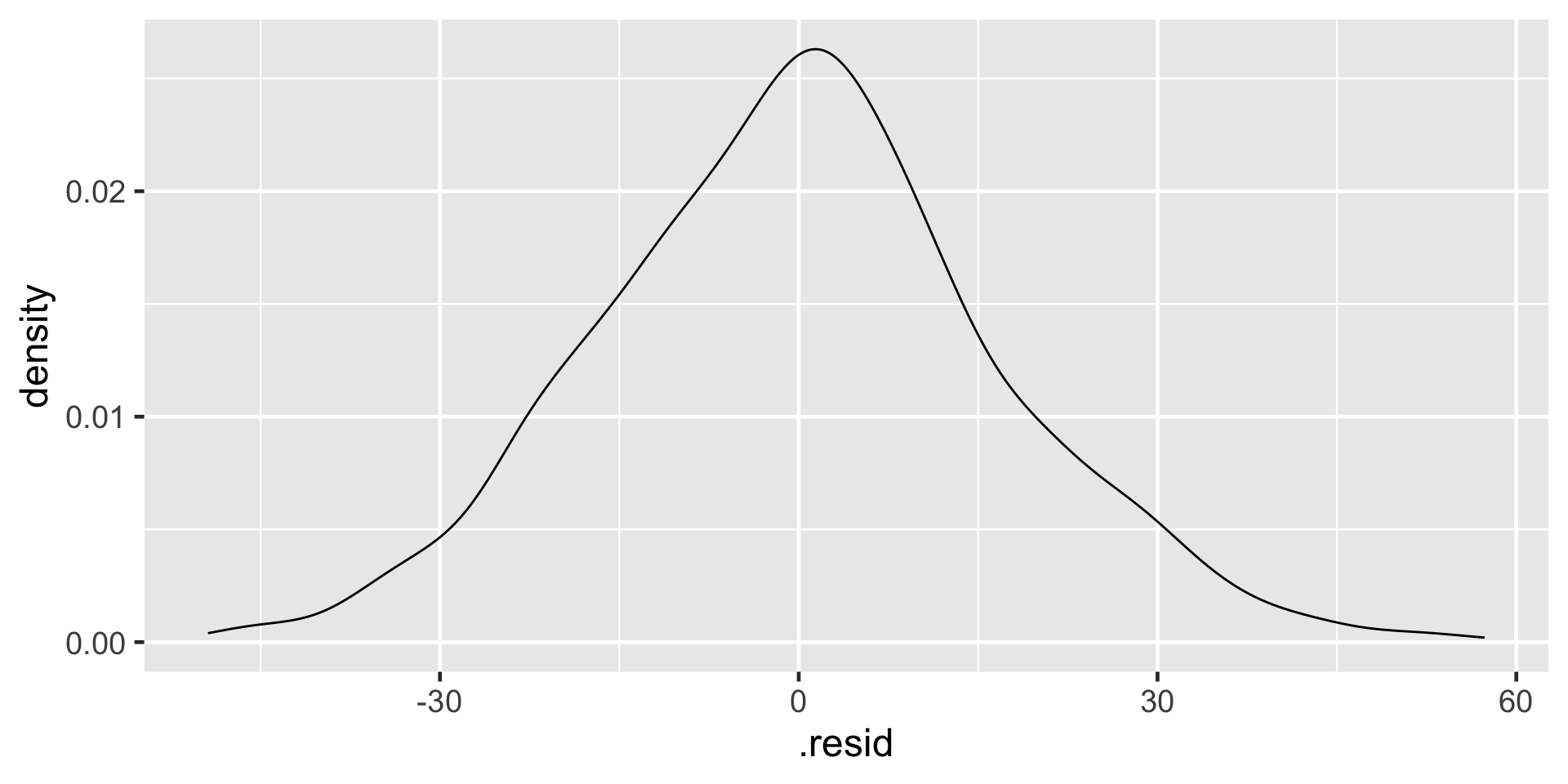
Nearly Normal Residuals
- Residuals should be nearly normal
- This condition can often be influenced by outliers
- While important, this condition can often be avoided through considering bootstrap procedures
Equal or Constant Variability
- The variability (scattered-ness) of the residual plot must be about the same throughout the plot.
- Data that do not satisfy this condition will potentially influence and mis-estimate the variability of the slope, impacting the inference
- A change in the variability as the explanatory variable increases means that predictions may not be reliable
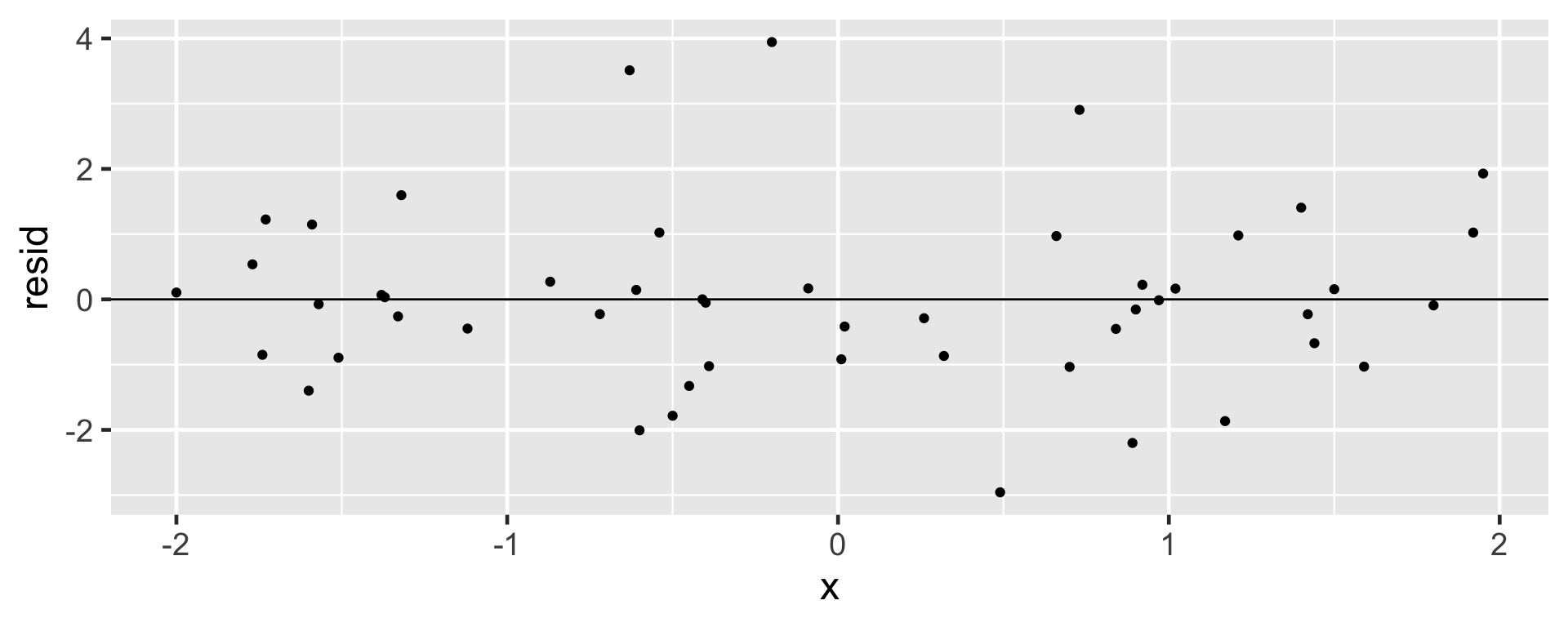
Non-constant Variance
Linearity: Using scattered plot
Linearity and constant variance: Using residual plot
- First, add residuals to your data. Next, plot the explanatory variable against the residuals and add a line through
y = 0
Normality of residuals
Testing Data
# A tibble: 1 × 12
r.squared adj.r.squared sigma statistic p.value df logLik AIC BIC
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 0.243 0.236 15.8 32.2 4.21e-18 3 -1272. 2553. 2572.
# ℹ 3 more variables: deviance <dbl>, df.residual <int>, nobs <int>[1] 15.64897